4.4 Example: Vector Addition¶
Let’s examine a relatively straightforward example that enables us to visualize the CUDA programming model and how to think when we have many cores. In linear algebra, vector addition is well-used operation, where vectors can be represented by arrays of values.
Figure 4-7 shows how vector addition on a GPU device works for the code you will see below (we show a small number of elements, but the real code will use much larger arrays). It also shows how we should think about how we will complete the work in parallel, by having each thread perform a single addition operation and compute a single new value for the result array. The green lines represent each thread of computation running simultaneously in parallel.
Using the CUDA programming model, we can think of having as many threads as we need to complete this type of task on larger arrays than depicted here- the system takes care of doing as much as possible in parallel with the available cores on your card, using the number of blocks you have set up in the grid, then reassigns them to do the rest; we don’t need to worry about that.
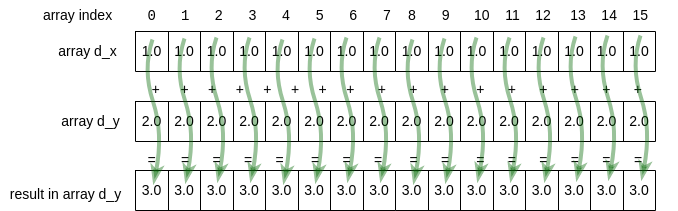
Figure 4-7: Each thread working on 1 array element¶
In this and the next two sections we will examine 3 versions of how we can complete this code.
First let’s describe in words what the first version of the CUDA code needs to do. Here are the steps, which match comments placed in the code found below.
Allocate 2 arrays, x and y, on the host and initialize them with data.
Allocate 2 arrays d_x, and d_y, on the GPU device.
Copy each of the arrays from the host to the device.
Perform the addition on the device using a kernel function, keeping result in d_y.
Ensure that the device is finished with the computation.
Copy the resulting array d_y from the device to the host, back into array y.
Check that the computation ran correctly.
Free memory on the device and the host.
New indispensable additions to the code¶
In a previous section (4.2 near the end), we mentioned that it is useful to check for errors that could be introduced into the code. This is true for both CUDA library calls used in the host code or functions you write for the device. CUDA provides some ways to enable you to examine errors that have occurred so that you can debug them. Observe a new macro provided at the top of the following example program file, then look further on in main to observe how it is used to check for problems that code on the device might have and report information about them.
It is always useful to be able to experiment with your application by changing sizes of various attributes to observe what happens. In C we can do this with command line arguments. In the case of this code, we have introduced a function called getArguments() that helps us allow the user to change certain parameters. We will see this in later examples also. In this case, the block size (number of threads per block) can be changed and the number of blocks needed in a grid is computed inside the code (look for that below).
When developing our code, we also need to develop mechanisms to ensure that the computation is correct. In this case, since we are testing by knowing we have placed 1.0 in each element of the array x (and copied to d_x) and 2.0 into the array y (and copied into d_y), we can test to be certain that every element in the result contains the value 3.0. This is shown in the function called verifyCorrect() in the code below.
The complete example¶
Filename: 2-vectorAdd/vectorAdd.cu
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 | //
// Demonstration using a single 1D grid and 1D block size
//
/*
* Example of vector addition :
* Array of floats x is added to array of floats y and the
* result is placed back in y
*
*/
#include <math.h> // ceil function
#include <stdio.h> // printf
#include <iostream> // alternative cout print for illustration
#include <cuda.h>
void initialize(float *x, float *y, int N);
void verifyCorrect(float *y, int N);
void getArguments(int argc, char **argv, int *blockSize);
///////
// error checking macro taken from Oakridge Nat'l lab training code:
// https://github.com/olcf/cuda-training-series
////////
#define cudaCheckErrors(msg) \
do { \
cudaError_t __err = cudaGetLastError(); \
if (__err != cudaSuccess) { \
fprintf(stderr, "Fatal error: %s (%s at %s:%d)\n", \
msg, cudaGetErrorString(__err), \
__FILE__, __LINE__); \
fprintf(stderr, "*** FAILED - ABORTING\n"); \
exit(1); \
} \
} while (0)
// Kernel function based on 1D grid of 1D blocks of threads
// In this version, thread number is:
// its block number in the grid (blockIdx.x) times
// the threads per block plus which thread it is in that block.
//
// This thread id is then the index into the 1D array of floats.
// This represents the simplest type of mapping:
// Each thread takes care of one element of the result
__global__ void vecAdd(float *x, float *y, int n)
{
// Get our global thread ID designed to be an array index
int id = (blockIdx.x * blockDim.x) + threadIdx.x;
// Make sure we do not go out of bounds;
// Threads allocated could be larger than array length
if (id < n)
y[id] = x[id] + y[id];
}
//////////////////// main
int main(int argc, char **argv)
{
printf("Vector addition by managing memory ourselves.\n");
// Set up size of arrays for vectors
int N = 32*1048576;
// TODO: try changng the size of the arrays by doubling or
// halving (32 becomes 64 or 16). Note how the grid size changes.
printf("size (N) of 1D arrays are: %d\n\n", N);
// host vectors, which are arrays of length N
float *x, *y;
// Size, in bytes, of each vector
size_t bytes = N*sizeof(float);
// 1.1 Allocate memory for each vector on host
x = (float*)malloc(bytes);
y = (float*)malloc(bytes);
// 1.2 initialize x and y arrays on the host
initialize(x, y, N); // set values in each vector
// device array storage
float *d_x;
float *d_y;
printf("allocate vectors and copy to device\n");
// 2. Allocate memory for each vector on GPU device
cudaMalloc(&d_x, bytes);
cudaMalloc(&d_y, bytes);
cudaCheckErrors("allocate device memory");
// 3. Copy host vectors to device
cudaMemcpy( d_x, x, bytes, cudaMemcpyHostToDevice);
cudaMemcpy( d_y, y, bytes, cudaMemcpyHostToDevice);
cudaCheckErrors("mem copy to device");
// Default number of threads in each thread block
int blockSize = 256;
getArguments(argc, argv, &blockSize); //update blocksize from cmd line
// Number of thread blocks in grid needs to be based on array size
// and block size
int gridSize = (int)ceil((float)N/blockSize);
printf("add vectors on device using grid with ");
printf("%d blocks of %d threads each.\n", gridSize, blockSize);
// 4. Execute the kernel
vecAdd<<<gridSize, blockSize>>>(d_x, d_y, N);
cudaCheckErrors("vecAdd kernel call");
// 5. Ensure that device is finished
cudaDeviceSynchronize();
cudaCheckErrors("Failure to synchronize device");
// 6. Copy array back to host (use original y for this)
// Note that essentially the device gets synchronized
// before this is performed.
cudaMemcpy( y, d_y, bytes, cudaMemcpyDeviceToHost);
cudaCheckErrors("mem copy device to host");
// 7. Check that the computation ran correctly
verifyCorrect(y, N);
printf("execution complete\n");
// 8.1 Free device memory
cudaFree(d_x);
cudaFree(d_y);
cudaCheckErrors("free cuda memory");
// 8.2 Release host memory
free(x);
free(y);
return 0;
}
///////////////////////// end main
///////////////////////////////// helper functions
// To initialize or reset the arrays for each trial
void initialize(float *x, float *y, int N) {
// initialize x and y arrays on the host
for (int i = 0; i < N; i++) {
x[i] = 1.0f;
y[i] = 2.0f;
}
}
// check whether the kernel functions worked as expected
void verifyCorrect(float *y, int N) {
// Check for errors (all values should be 3.0f)
float maxError = 0.0f;
for (int i = 0; i < N; i++)
maxError = fmaxf(maxError, fabs(y[i]-3.0f));
std::cout << "Max error: " << maxError << std::endl;
}
// simple argument gather for this simple example program
void getArguments(int argc, char **argv, int *blockSize) {
if (argc == 2) {
*blockSize = atoi(argv[1]);
}
}
|
This code is designed to use a default block size of 256 threads and let you change it as the single command line argument. Find how this is done in the code above. Block sizes of 128, 256, or 512 are typical for many NVIDIA architectures (we will examine how this may change performance later). This is because most of today’s NVIDIA cards have 128 cores per streaming multiprocessor (SM). We leave it as an exercise for you to try different block sizes.
Use array size and block size to set grid size¶
Note line 101 above, repeated here:
int gridSize = (int)ceil((float)N/blockSize);
Since in most code we may want to vary the size of our arrays, this illustrates the best practice for ensuring that is possible. Given a particular block size and number of elements, we can decide how many thread blocks should be in the 1D grid that will work on each data element.
Obtaining an array index for a thread¶
In the previous section, we provided this function to compute a unique value, beginning with 0, to use as an index into any array. It looks like this:
// Given a 1 dimensional grid of blocks of threads,
// determine my thread number.
// This is run on the GPU on each thread.
__device__ int find1DThreadNumber() {
// illustrative variable names
int threadsPerBlock_horizontal = blockDim.x;
int gridBlockNumber = blockIdx.x;
int threadNumber = (gridBlockNumber * threadsPerBlock_horizontal) + threadIdx.x;
return threadNumber;
}
In the vectorAdd program above, we use this same concept in the vecAdd kernel function, repeated here:
__global__ void vecAdd(float *x, float *y, int n)
{
// Get our global thread ID designed to be an array index
int id = (blockIdx.x * blockDim.x) + threadIdx.x;
// Make sure we do not go out of bounds;
// Threads allocated could be larger than array length
if (id < n)
y[id] = x[id] + y[id];
}
Convince yourself these are both obtaining indexes for arrays and that in the case of the vecAdd function each thread is now completing one addition operation and populating one element of the array.
Note
An important check is being done in the above vecAdd function. We should always check that a thread id to be used as an index into an array does not point outside of the bounds of the array before we attempt the computation.
Build and run¶
You can use the make command on your own machine or compile the code like this:
nvcc -arch=native -o vectorAdd vectorAdd.cu
Remember that you will need to use a different -arch flag if native does not work for you. (See note at end of section 4.1.)
You can execute this code like this:
./vectorAdd
Vector addition by managing memory ourselves.
size (N) of 1D arrays are: 33554432
allocate vectors and copy to device
add vectors on device using grid with 131072 blocks of 256 threads each.
Max error: 0
execution complete
Exercises¶
4.4-1. Try using different block sizes of 128 and 512 to be certain that the code is still correct.
4.4-2. If you are ambitious, you could try changing the command line arguments (if you are familiar with this) to include a length for the arrays. Or more simply, change the code to change the size of the array, N, as shown early in the main function. This is useful to verify the code is still correct. Later we will see that it is useful for trying different problem sizes to see how the code performs.